

Eredeti cikk:https://faculty.cc.gatech.edu/~parikh/nameable.html
Devi Parikh és Kristen Grauman
[ spanyolul ]
Absztrakt
Az ember által megnevezett vizuális attribútumok számos előnnyel járnak, ha középszintű objektumfelismerési funkciókként használják őket, de a releváns attribútumok összegyűjtésére szolgáló meglévő technikák nem hatékonyak (jelentős erőfeszítésbe vagy szakértelembe kerülnek) és/vagy elégtelenek (a leíró tulajdonságoknak nem kell megkülönböztetőnek lenniük). Bemutatunk egy olyan megközelítést, amellyel meghatározhatjuk az attribútumok szókészletét, amely egyszerre érthető és megkülönböztető. A rendszer bemenetként objektum/jelenet címkézett képeket vesz fel, és kimenetként visszaadja az emberi annotátorok által kiváltott attribútumok készletét, amelyek megkülönböztetik az érdeklődésre számot tartó kategóriákat. A tömör szókincs és az annotátorok erőfeszítéseinek hatékony felhasználása érdekében 1) megmutatjuk, hogyan lehet aktívan bővíteni a szókincset úgy, hogy az új attribútumok megoldják az osztályok közötti zavarokat, és 2) javasoljon egy újszerű "nevezhetőség" sokaságot, amely a jelölt tulajdonságokat prioritásként kezeli annak alapján, hogy milyen valószínűséggel társulnak egy megnevezhető tulajdonsághoz. A megközelítést több adatkészlettel mutatjuk be, és megmutatjuk annak egyértelmű előnyeit azokkal az alapvonalakkal szemben, amelyekből hiányzik az elnevezési modell, vagy amelyek szakértők által biztosított attribútumok listájára támaszkodnak.
Motiváció
Ahhoz, hogy a leghasznosabbak legyenek, az attribútumoknak olyannak kell lenniük
Megkülönböztető : hogy a rendelkezésre álló jellemzőtérben megbízhatóan tanulhatók legyenek, és hatékonyan osztályozhassák a kategóriákat
és
Nevezhető: így használhatók zero-shot tanulásra, korábban nem látott esetek vagy képek szokatlan aspektusainak leírására stb.
| Meglévő megközelítések | Megkülönböztető | Nevezhető |
| Kézzel generált lista | Nem feltétlenül | Igen |
| A web bányászata | Nem feltétlenül | Igen |
| A kategóriák automatikus felosztása | Igen | Nem |
| Javasolt | Igen | Igen |
Javaslat
Olyan interaktív megközelítést javasolunk, amely arra készteti a hurokban lévő embert, hogy adjon nevet az általa felfedezett attribútum-hipotéziseknek. A rendszer bemenetként veszi a képzési képek halmazát a hozzájuk tartozó kategóriacímkékkel, valamint egy vagy több vizuális jellemzőteret (Lényeg, szín stb.), és kimenetként olyan attribútummodelleket ad vissza, amelyek együttesen meg tudják különböztetni a kategóriákat. érdeklődés.
Egy olyan jelölt attribútum megjelenítéséhez, amelyhez a rendszer nevet keres, az embernek képeket jelenítenek meg a jellemző térben lévő elválasztó hipersíkra merőleges irányban. Mivel sok hipotézis nem felel meg valaminek, amit az emberek vizuálisan azonosíthatnak és tömören leírhatnak, a naiv attribútum-felfedezési folyamat – amelyik egyszerűen végighalad a megkülönböztető felosztásokon, és megkéri az annotátort, hogy nevezze meg vagy utasítsa el őket – nem praktikus.
Ehelyett úgy tervezzük meg a megközelítést, hogy aktívan minimalizáljuk az annotátornak benyújtott értelmetlen kérdések mennyiségét, így az emberi erőfeszítést többnyire arra kell fordítani, hogy jelentést rendeljünk a jellemzőtér azon felosztásaihoz, amelyekben ez ténylegesen van, ahelyett, hogy elvetnénk az értelmezhetetlen felosztásokat.
Ezt két kulcsfontosságú ötlettel érjük el: minden iterációnál a mi megközelítésünk:
1) olyan attribútum-hipotézisekre összpontosít, amelyek kiegészítik az eddig összegyűjtött meglévő attribútumok osztályozási erejét, és
2) megjósolja az egyes diszkriminatív hipotézisek megnevezhetőségét, és előtérbe helyezi azokat, amelyek valószínűleg megnevezhetők. Ehhez megvizsgáljuk, hogy létezik-e valamilyen sokrétű struktúra a megnevezhető hipersík elválasztók terében.

Megközelítés
A javasolt interaktív megközelítésben három fő kihívással kell foglalkozni:
Attribútum-hipotézisek felfedezése: Aktívan felfedezünk hipersíkokat a vizuális jellemző-térben, amelyek elválasztják a jelenleg leginkább zavart osztályok egy részét. Iteratív max-margin klaszterezést használunk egy ilyen felosztás felfedezéséhez.
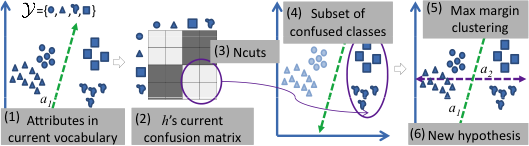
Egy hipotézis megnevezhetőségének előrejelzése : Minden iterációnál létrehozunk egy elnevezési sokaságot a valószínűségi főkomponens-elemzés keverékével, hogy illeszkedjen a felhasználó eddig összegyűjtött válaszaihoz . A sokaság megtanulása a hipersík paraméterek terében történik. Amint az alábbiakban látható, a sokaság hatékonyan megjósolhatja egy új diszkriminatív hipersík elnevezését.

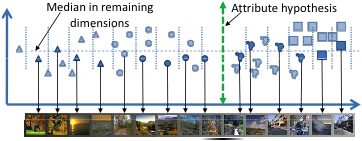
Egy attribútum megjelenítése: Annak érdekében, hogy a felhasználó számára egy hipersík vizualizációját mutassuk be, mintákat veszünk az adatkészletből úgy, hogy a hipersíkra merőleges távolságuk változzon, de a hipersík mentén minden eltérés minimális legyen. Ezután a felhasználónak meg kell neveznie egy vizuális tulajdonságot, amely balról jobbra változik a képeken. Ez a név a hipersík paraméterekkel együtt alkotja az újonnan felfedezett attribútumunkat.
Értékelés
Megközelítésünket két, egyenként 8 kategóriából álló adatkészleten értékeljük: a kültéri jelenetfelismerés (OSR) és az Animals with Attributes (AWA) adatkészlet egy részhalmaza alapján. Mindkét adatkészlethez lényegi és színfunkciókat használunk.
Javasolt megközelítésünk automatikus kiértékelése érdekében összegyűjtjük az összes megkülönböztető hipersík elnevezési annotációit (247) mindkét adatkészlet mindkét jellemzőterében. Mindegyik hipersík vizualizációját mutatjuk be 20 Amazon Mechanical Turk alanynak, és megkérjük őket, hogy jelezzék, mennyire nyilvánvaló a változás a képeken (1-4-ig terjedő skálán), és mi a változó tulajdonság. Példaválaszok az alábbiakban láthatók:
"Fekete"

"Észlelve"

Megnevezhetetlen

"Zöld"

"Zsúfolt"

A hipersíkot akkor tekintjük nevezhetőnek, ha a kapott átlagos „nyilvánvalósági” pontszám 3 felett van. Ez a jegyzett hipersík-készlet most már használható automatikus kísérletek elvégzésére, miközben továbbra is valódi felhasználót imitál a hurokban.
Eredmények
Csak diszkriminatív alapvonal: Egy olyan alapvonalhoz képest, amely a megkülönböztető hipersíkokat a felhasználó számára elnevezési modellezés nélkül mutatja be (lásd alább), azt találjuk, hogy megközelítésünk több elnevezett attribútumot fedez fel azonos felhasználói erőfeszítéssel, ami szintén jobb felismerési teljesítményt eredményez.
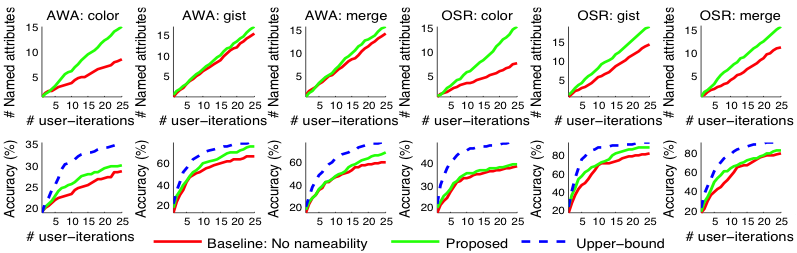
Csak leíró alaphelyzet: Másrészt a tisztán leíró tulajdonságokhoz képest megközelítésünk több megkülönböztető tulajdonságot talál, ami szintén jobb felismerési teljesítményt eredményez (lásd alább).

Automatikusan generált leírások: Felfedezett attribútumaink felhasználhatók korábban látott és korábban nem látott (pl. zerba) képek leírására, ahogy az alább látható.

Publikációk
Megnevezhető tulajdonságok megkülönböztető szókincsének interaktív felépítése
IEEE konferencia a számítógépes látásról és mintafelismerésről (CVPR), 2011
[ kiegészítő anyag ] [ poszter ] [ diák ]
Feladat-specifikus megnevezhető attribútumok interaktív felfedezése (absztrakt)
Első workshop a finomszemcsés vizuális kategorizációról (FGVC)
az IEEE Computer Vision and Pattern Recognition (CVPR) konferenciájával együtt, 20 11 (A legjobb poszter díja)
[ poszter ]